Dataset Statistics
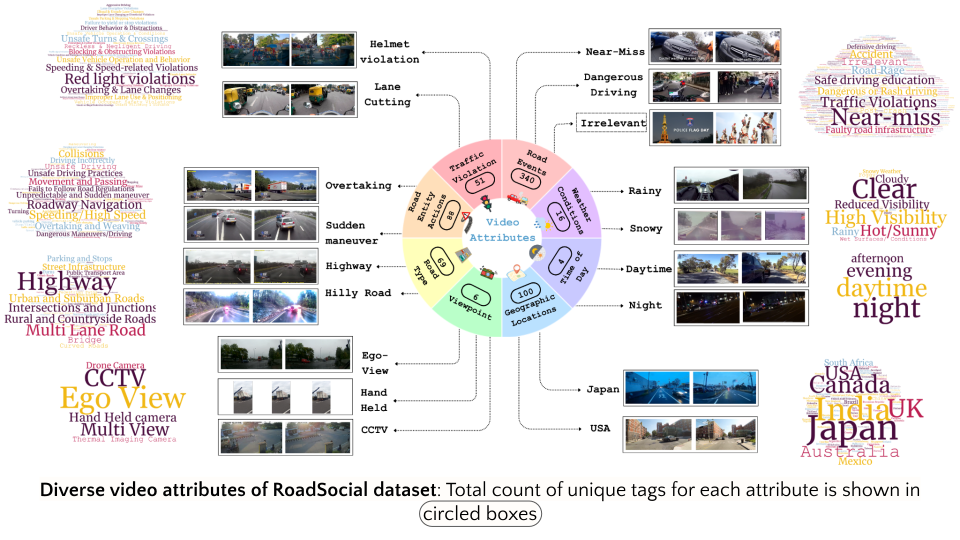
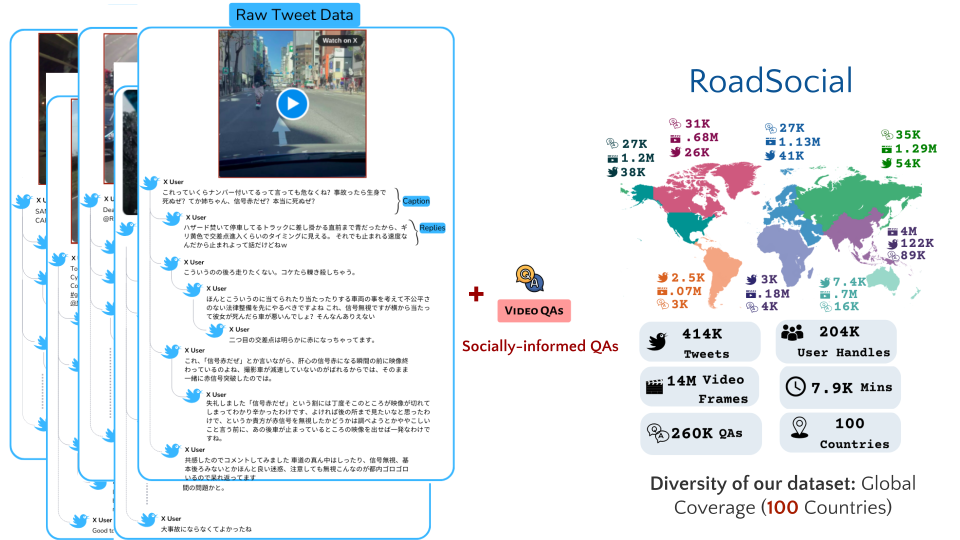
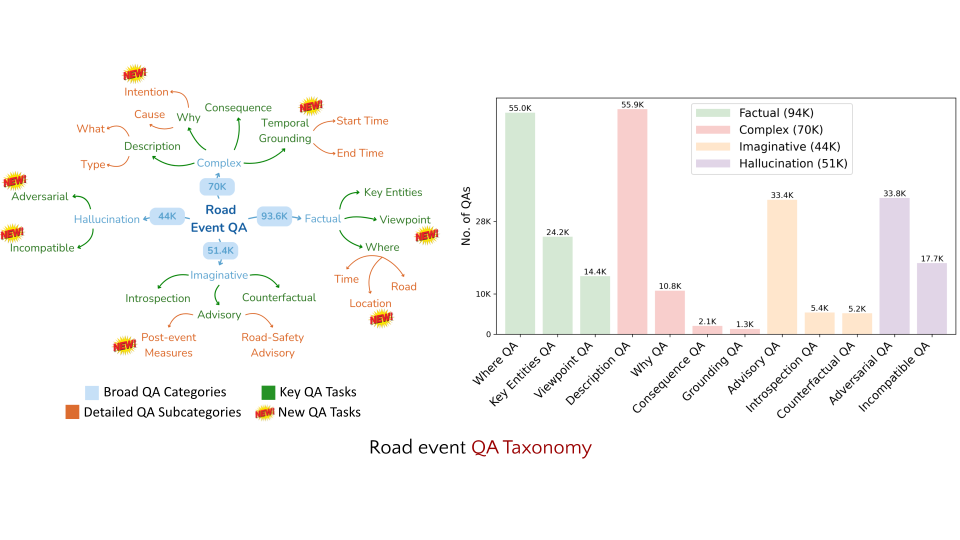
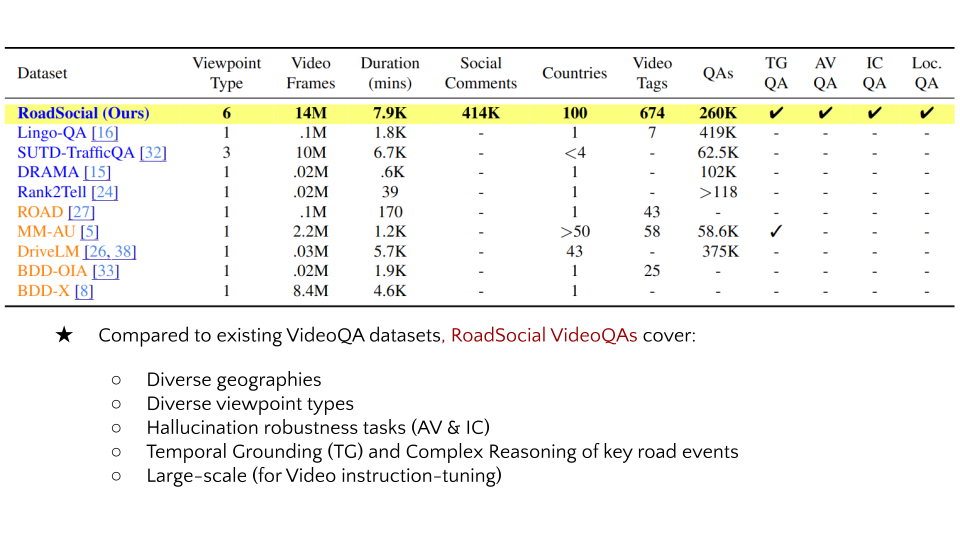


RoadSocial is a large-scale, diverse VideoQA dataset tailored for generic road event understanding from social media narratives. It differentiates itself from existing datasets by capturing the global complexity of road events with varied geographies, camera viewpoints (CCTV, handheld, drones) and rich social discourse. RoadSocial highlights:
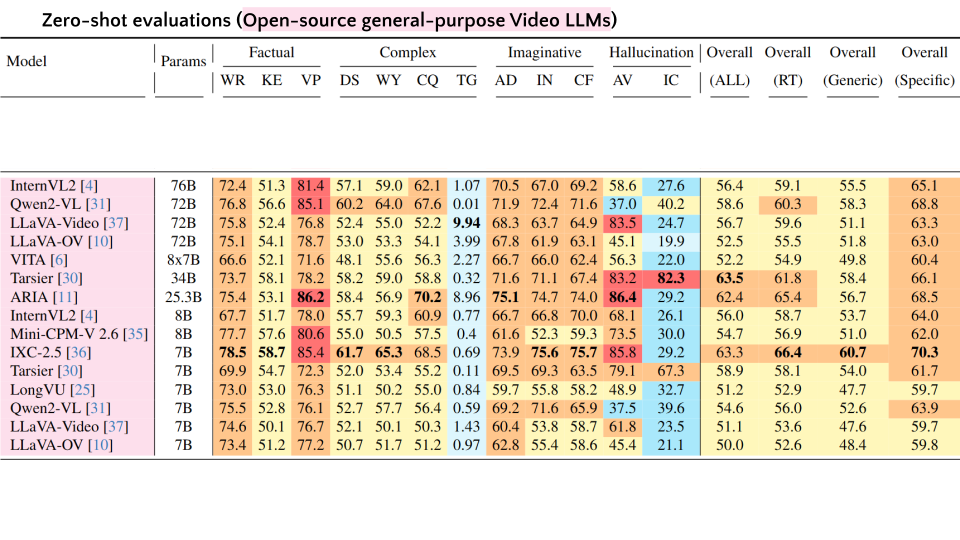
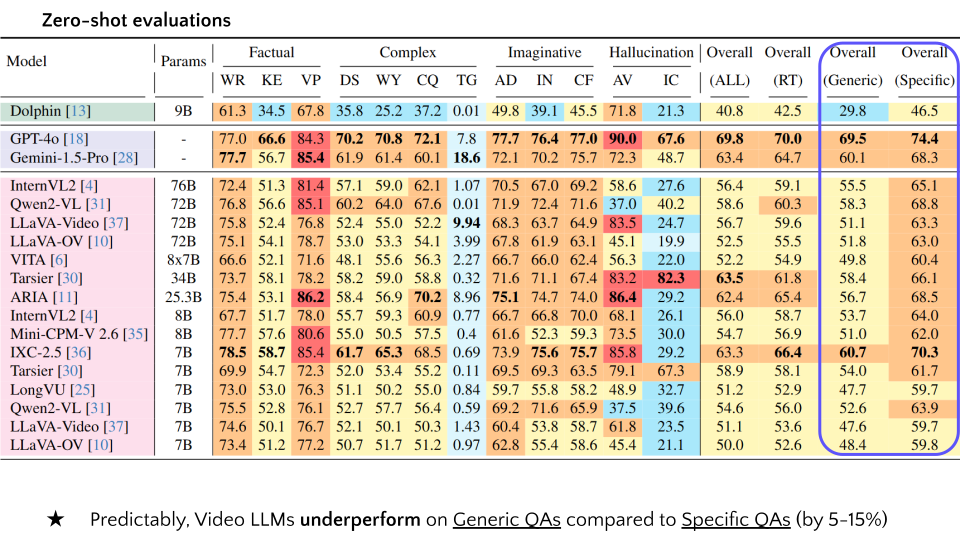
| # | Model | Params | Factual | Complex | Imaginative | Hallucination | Overall | Overall | Overall | Overall | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| WR | KE | VP | DS | WY | CQ | TG | AD | IN | CF | AV | IC | (ALL) | (RT) | (Generic) | (Specific) | |||
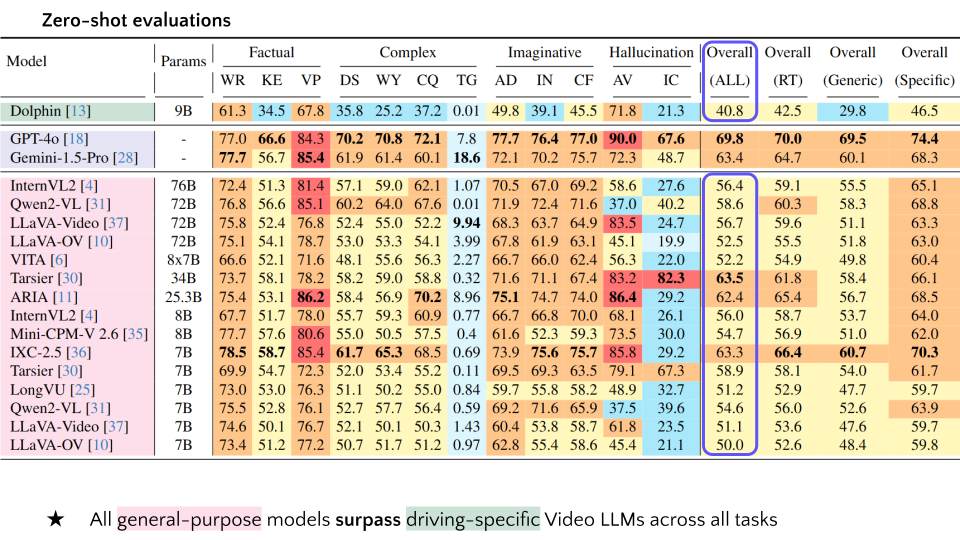
| 1 | Dolphin | 9B | 61.3 | 34.5 | 67.8 | 35.8 | 25.2 | 37.2 | 0.01 | 49.8 | 39.1 | 45.5 | 71.8 | 21.3 | 40.8 | 42.5 | 29.8 | 46.5 |
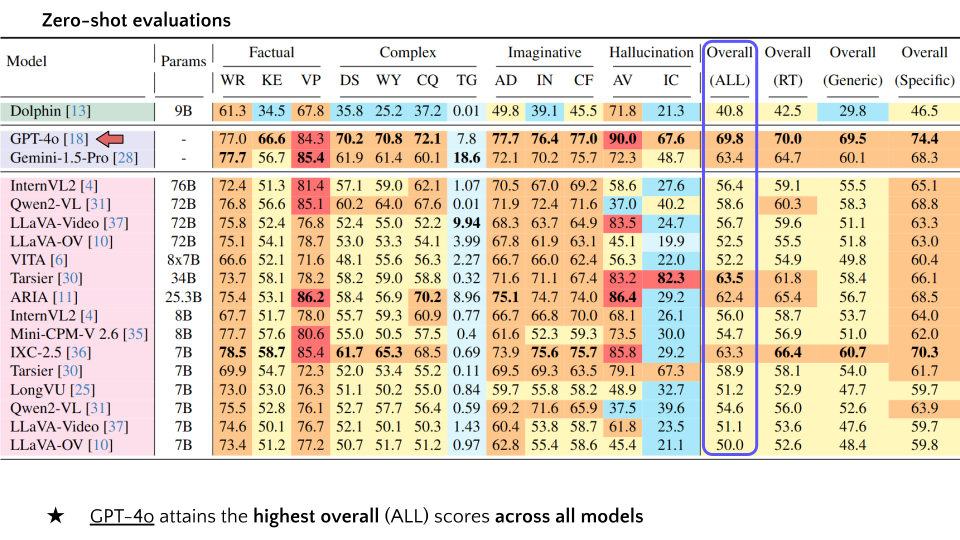
| 2 | GPT-4o | - | 77.0 | 66.6 | 84.3 | 70.2 | 70.8 | 72.1 | 7.8 | 77.7 | 76.4 | 77.0 | 90.0 | 67.6 | 69.8 | 70.0 | 69.5 | 74.4 |
| 3 | Gemini-1.5-Pro | - | 77.7 | 56.7 | 85.4 | 61.9 | 61.4 | 60.1 | 18.6 | 72.1 | 70.2 | 75.7 | 72.3 | 48.7 | 63.4 | 64.7 | 60.1 | 68.3 |
| 4 | InternVL2 | 76B | 72.4 | 51.3 | 81.4 | 57.1 | 59.0 | 62.1 | 1.07 | 70.5 | 67.0 | 69.2 | 58.6 | 27.6 | 56.4 | 59.1 | 55.5 | 65.1 |
| 5 | Qwen2-VL | 72B | 76.6 | 56.6 | 85.1 | 60.2 | 64.0 | 67.6 | 0.01 | 71.9 | 72.4 | 71.6 | 37.0 | 40.2 | 58.6 | 60.3 | 58.3 | 68.8 |
| 6 | LLaVA-Video | 72B | 75.8 | 52.4 | 76.8 | 52.4 | 55.0 | 52.2 | 9.94 | 68.3 | 63.7 | 64.9 | 83.5 | 24.7 | 56.7 | 59.6 | 51.1 | 63.3 |
| 7 | LLaVA-OV | 72B | 75.1 | 54.1 | 78.7 | 53.0 | 53.3 | 54.1 | 3.99 | 67.8 | 61.9 | 63.1 | 45.1 | 19.9 | 52.5 | 55.5 | 51.8 | 63.0 |
| 8 | VITA | 8x7B | 66.6 | 52.1 | 71.6 | 48.1 | 55.6 | 56.3 | 2.27 | 66.7 | 66.0 | 62.4 | 56.3 | 22.0 | 52.2 | 54.9 | 49.8 | 60.4 |
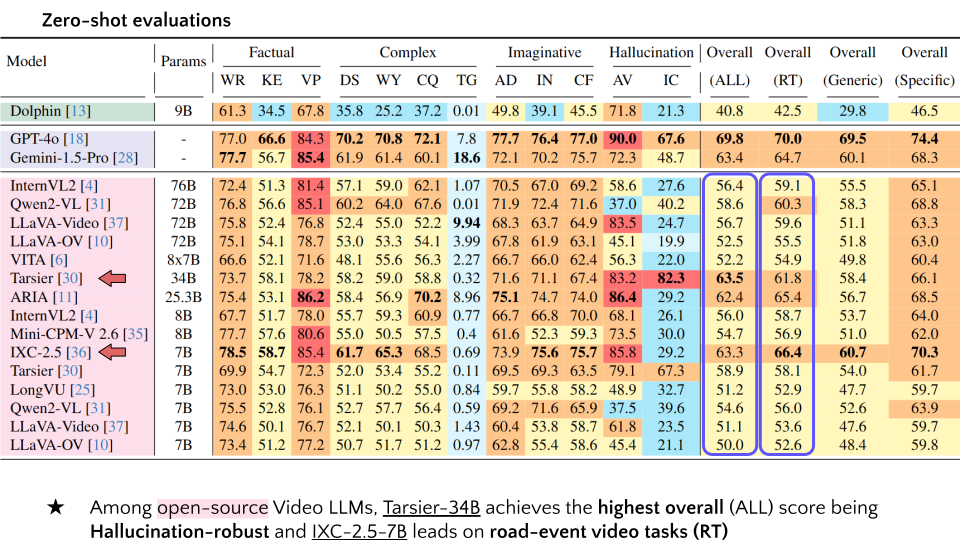
| 9 | Tarsier | 34B | 73.7 | 58.1 | 78.2 | 58.2 | 59.0 | 58.8 | 0.32 | 71.6 | 71.1 | 67.4 | 83.2 | 82.3 | 63.5 | 61.8 | 58.4 | 66.1 |
| 10 | ARIA | 25.3B | 75.4 | 53.1 | 86.2 | 58.4 | 56.9 | 70.2 | 8.96 | 75.1 | 74.7 | 74.0 | 86.4 | 29.2 | 62.4 | 65.4 | 56.7 | 68.5 |
| 11 | InternVL2 | 8B | 67.7 | 51.7 | 78.0 | 55.7 | 59.3 | 60.9 | 0.77 | 66.7 | 66.8 | 70.0 | 68.1 | 26.1 | 56.0 | 58.7 | 53.7 | 64.0 |
| 12 | Mini-CPM-V 2.6 | 8B | 77.7 | 57.6 | 80.6 | 55.0 | 50.5 | 57.5 | 0.4 | 61.6 | 52.3 | 59.3 | 73.5 | 30.0 | 54.7 | 56.9 | 51.0 | 62.0 |
| 13 | IXC-2.5 | 7B | 78.5 | 58.7 | 85.4 | 61.7 | 65.3 | 68.5 | 0.69 | 73.9 | 75.6 | 75.7 | 85.8 | 29.2 | 63.3 | 66.4 | 60.7 | 70.3 |
| 14 | Tarsier | 7B | 69.9 | 54.7 | 72.3 | 52.0 | 53.4 | 55.2 | 0.11 | 69.5 | 69.3 | 63.5 | 79.1 | 67.3 | 58.9 | 58.1 | 54.0 | 61.7 |
| 15 | LongVU | 7B | 73.0 | 53.0 | 76.3 | 51.1 | 50.2 | 55.0 | 0.84 | 59.7 | 55.8 | 58.2 | 48.9 | 32.7 | 51.2 | 52.9 | 47.7 | 59.7 |
| 16 | Qwen2-VL | 7B | 75.5 | 52.8 | 76.1 | 52.7 | 57.7 | 56.4 | 0.59 | 69.2 | 71.6 | 65.9 | 37.5 | 39.6 | 54.6 | 56.0 | 52.6 | 63.9 |
| 17 | LLaVA-Video | 7B | 74.6 | 50.1 | 76.7 | 52.1 | 50.1 | 50.3 | 1.43 | 60.4 | 53.8 | 58.7 | 61.8 | 23.5 | 51.1 | 53.6 | 47.6 | 59.7 |
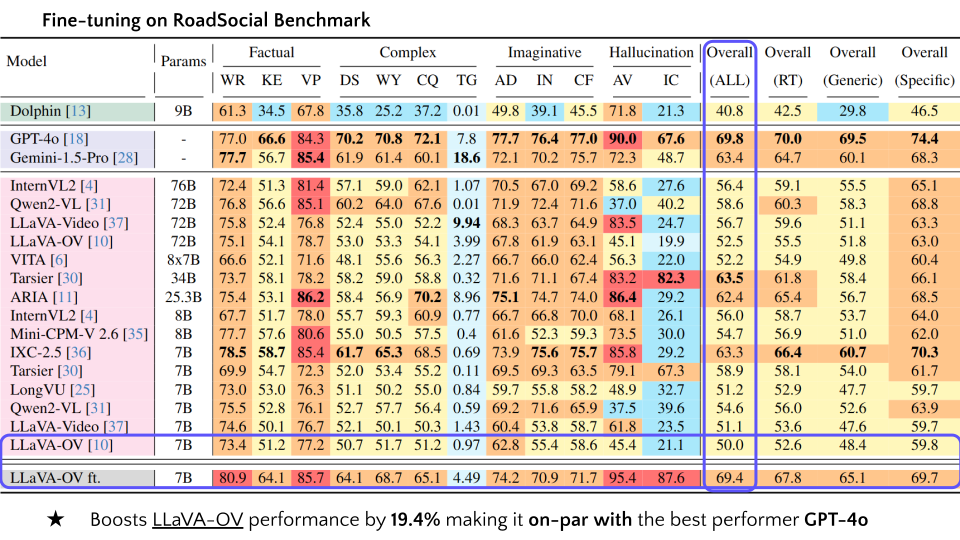
| 18 | LLaVA-OV | 7B | 73.4 | 51.2 | 77.2 | 50.7 | 51.7 | 51.2 | 0.97 | 62.8 | 55.4 | 58.6 | 45.4 | 21.1 | 50.0 | 52.6 | 48.4 | 59.8 |
| 19 | LLaVA-OV ft. | 7B | 80.9 | 64.1 | 85.7 | 64.1 | 68.7 | 65.1 | 4.49 | 74.2 | 70.9 | 71.7 | 95.4 | 87.6 | 69.4 | 67.8 | 65.1 | 69.7 |
Submit your results: chirag.parikh@research.iiit.ac.in
References: InternVL2 [4]; MM-AU [5]; VITA [6]; BDD-X [8]; LLaVA-OV [10]; ARIA [11]; Dolphin [13]; DRAMA [15]; LingoQA [16]; GPT-4o [18]; Rank2Tell [24]; LongVU [25]; DriveLM [26]; ROAD [27]; Gemini-1.5-Pro [28]; Tarsier [30]; Qwen2-VL [31]; SUTD-TrafficQA [32]; BDD-OIA [33]; Mini-CPM-V [35]; IXC-2.5 [36]; LLaVA-Video [37]
@misc{parikh2025roadsocialdiversevideoqadataset,
title={RoadSocial: A Diverse VideoQA Dataset and Benchmark for Road Event Understanding from Social Video Narratives},
author={Chirag Parikh and Deepti Rawat and Rakshitha R. T. and Tathagata Ghosh and Ravi Kiran Sarvadevabhatla},
year={2025},
eprint={2503.21459},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.21459},
}